Breaking Free from Sequential Thinking: The Free Transformer Architecture
Imagine you're writing a movie review. Before typing the first word, you already know whether you'll praise or criticize the film. This high-level decision shapes every sentence that follows. Yet standard language models lack this ability; they generate text one word at a time, inferring their "plan" only from the words they've already written. The Free Transformer, proposed by François Fleuret at Meta FAIR, introduces a radical shift: what if the model could make explicit, high-level decisions before generating tokens? This architecture extends the decoder Transformer with learned latent variables that capture abstract plans, allowing the model to separate strategic choices from tactical execution.
https://github.com/udapy/free-transformer
The Sequential Trap
Standard decoder Transformers are purely autoregressive. They model a sequence S = (S₁, ..., Sₜ) using the chain rule: P(S) = ∏ᵗₜ₌₁ P(Sₜ | S₁, ..., Sₜ₋₁) Generation proceeds token by token, with each prediction conditioned only on what came before. The model has no mechanism for making abstract, upfront decisions about the structure or direction of the sequence.
What is an Autoregressive Model?
An autoregressive model generates sequences by predicting one element at a time, where each prediction depends only on previous elements. While powerful, this approach forces the model to implicitly encode high-level concepts (like sentiment, topic, or style) through the concrete tokens themselves. There's no explicit "planning" step—the model must constantly infer its implicit plan from the tokens generated so far, which can be computationally demanding and fragile.
The Problem in Practice
Consider the movie review scenario. A well-trained Transformer generating reviews for a good movie will produce 90% positive and 10% negative reviews, matching the training distribution. But how does it decide which type to generate? The answer lies in token sampling. Early in generation, the model might produce "This movie is..." followed by either "brilliant" or "disappointing." Once this critical token is sampled, self-consistency forces all subsequent tokens to align. The model doesn't make an upfront decision about sentiment, it discovers its implicit plan through the tokens themselves.
This creates three fundamental problems:
- Unnecessary Complexity: The model must constantly estimate latent concepts from generated tokens, requiring greater capacity.
- Fragility: A few ambiguous or erroneous early tokens can derail the entire sequence.
- Inefficient Structuring: High-level concepts emerge post-hoc rather than guiding generation from the start.
The Mathematical Cost
The paper illustrates this mathematically. Consider a latent variable Z ~ Bernoulli(0.5) (a coin flip) and tokens X₁, ..., Xₜ that match Z with probability 1 - ε. With access to Z, the conditional probability is simple:
P(Xₜ₊₁ = 1 | Z = z) = εz + (1 - ε)(1 - z) But without Z, the autoregressive model must reverse-engineer the coin flip from observed tokens: P(Xₜ₊₁ = 1 | X₁ = x₁, ..., Xₜ = xₜ) = [(1-ε)∑ᵢxᵢ + ε(t - ∑ᵢxᵢ)] / t The second expression is far more complex, requiring running estimates over all past tokens. This exemplifies how forcing latent-variable processes into purely autoregressive molds creates unnecessary computational burden.
The Core Innovation: Latent Plans
The Free Transformer's solution is elegant: introduce an explicit latent variable Z that captures high-level decisions before token generation begins. This separates the stochastic choice of "what to say" from the deterministic process of "how to say it."
Think of Z as the model's internal decision: "I will write a positive review" or "The main character will face a moral dilemma." Once this decision is made, every subsequent token can reference it, leading to simpler, more consistent generation.
Understanding Z :
In the Free Transformer, Z is a sequence of T one-hot vectors, where each Zₜ has dimension 2¹⁶ = 65,536. At each token position t, the model chooses one of 65,536 possible "micro-plans." This high-dimensional discrete space allows the model to represent complex abstract concepts. During inference, Z is sampled from a uniform prior distribution, giving the model "freedom" to explore different generative paths. During training, an encoder infers the appropriate Z from the full sequence.
Why 65,536 Choices?
The latent variable is constructed from H = 16 independent binary bits, giving 2¹⁶ = 65,536 possible values per token position. This dimensionality is comparable to the vocabulary size (approximately 2¹⁷), providing enough expressiveness to capture meaningful structure without overwhelming the model.
The key insight: by conditioning generation on P(S | Z) instead of just P(S), the model transforms a complex marginal distribution into a simpler conditional one, guided by explicit latent plans.
Architecture: Two Modes, One Model
The Free Transformer operates fundamentally differently during training versus inference. This dual-mode design elegantly separates learning from generation.
Two-Mode Operation:
- Training Mode: Uses an encoder to infer Z from the complete sequence. The encoder "cheats" by looking ahead at the full text, determining what latent plan would have produced it. This teaches the decoder to follow plans.
- Inference Mode: Discards the encoder entirely. Samples Z from a simple uniform distribution, giving the decoder a random plan to follow. Because the decoder learned to interpret Z during training, it generates coherent text even with random plans.
The following diagram illustrates this fundamental architectural difference between training and inference modes:
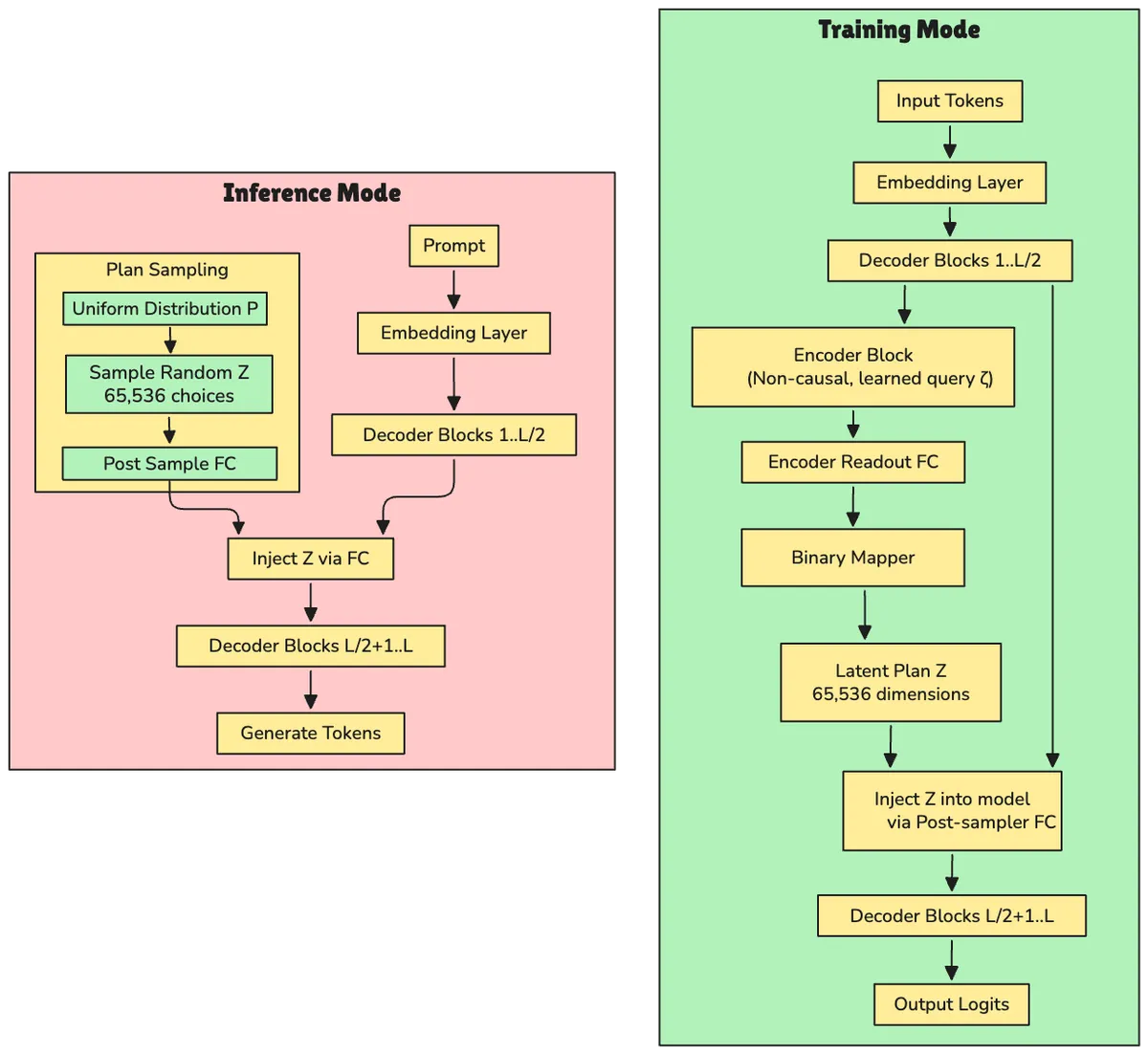 Figure 1 :The Free Transformer operates in two distinct modes. During training (top), an encoder infers latent plans Z from complete sequences, teaching the decoder to interpret abstract plans. During inference (bottom), the encoder is discarded and Z is sampled randomly from a uniform distribution, giving the model freedom to explore different generative paths.[1]
Figure 1 :The Free Transformer operates in two distinct modes. During training (top), an encoder infers latent plans Z from complete sequences, teaching the decoder to interpret abstract plans. During inference (bottom), the encoder is discarded and Z is sampled randomly from a uniform distribution, giving the model freedom to explore different generative paths.[1]
Training Mode: Learning to Follow Plans
During training, the model follows this flow:
Input Sequence → Embedding Layer → Decoder Blocks 1 to L/2 → Encoder Block (Non-Causal) → Encoder Readout → Binary Mapper → Sample Z → Post-sampler Projection → Injection Point → Decoder Blocks L/2+1 to L → Final Readout → Output Logits
The process breaks down into these steps:
- The input sequence passes through the first half of decoder blocks (L/2 layers).
- An encoder (a single non-causal Transformer block) processes this intermediate representation.
- The encoder outputs logits that are sampled to produce Z via the Binary Mapper.
- Z is projected and injected into the middle of the decoder.
- The second half of decoder blocks continues processing, now conditioned on Z.
- Final logits are computed for next-token prediction.
The Encoder's Special Power: The encoder is a single Transformer block with non-causal self-attention, meaning it can attend to all tokens in the sequence—both past and future. This is essential because the latent plan for a sequence might depend on information that appears later in the text. The encoder takes the output of the first half of decoder blocks as its keys and values, but uses a learned query vector ζ (zeta) replicated across all positions. This design forces the encoder to extract global properties rather than performing token-wise mappings. Output: H = 16 logits per token position, which are then converted to the discrete latent variable Z.
The encoder "cheats" during training; it sees the entire sequence, including future tokens. This allows it to infer what latent plan would best explain the observed text. The decoder learns to follow these plans.
Inference Mode: Free to Choose
At inference time, the architecture simplifies dramatically:
Prompt → Embedding Layer →
Decoder Blocks 1 to L/2 →
[Uniform Distribution P(Z)] → Sample Random Z →
Post-sampler Projection →
Injection Point →
Decoder Blocks L/2+1 to L →
Final Readout →
Generate Next Token
The key differences:
- The prompt passes through the first half of decoder blocks.
- The encoder is discarded.
- Z is simply sampled uniformly from {0, ..., 2¹⁶-1}ᵀ.
- This random Z is injected into the decoder.
- The second half generates tokens conditioned on both the prompt and the random plan.
How Z Gets Injected: After sampling (or inferring) Z, it is projected through a linear layer transforming the one-hot vector (dimension 2¹⁶) back to the model's hidden dimension D. This projection r is added to the output x from the first decoder half. The sum x + r is used as keys and values for the attention mechanism in block L/2 + 1, while queries remain just x. This asymmetric injection means the model "queries" its token-based context x against a combined representation of context and plan x + r, allowing the plan to modulate all subsequent processing.
The "freedom" in Free Transformer comes from this random sampling. The model explores different high-level generative paths by varying Z, even with identical prompts.
The Technical Machinery
The Learned Query Vector
A clever design choice ensures the encoder captures global structure rather than token-level details.
The ζ (Zeta) Trick: Instead of using token representations as queries for the encoder's attention mechanism, the Free Transformer uses a single learned embedding vector ζ (zeta) that is replicated T times (once per token position). Why this design? It prevents the encoder from simply creating a token-wise mapping (copying information position-by-position). By using a constant query across all positions, the encoder is forced to aggregate information and capture global properties of the sequence; exactly what a high-level "plan" should represent.
The Binary Mapper: Bridging Continuous and Discrete
The encoder outputs continuous logits, but Z must be discrete (one-hot vectors). Directly sampling discrete values is non-differentiable, blocking gradient flow to the encoder. The Binary Mapper solves this with an elegant trick.
The process works as follows:
Logits to Probabilities: For each of H = 16 positions, compute bit probabilities using sigmoid: P(Bₜ,ₕ = 1) = 1 / (1 + e⁻ᴸᵗ'ʰ)
Sample Bits: Sample each bit independently according to these probabilities.
Bits to Integer: Combine the H bits into a decimal index d ∈ {0, ..., 2¹⁶-1}, then create a one-hot vector.
Gradient Pass-Through: Use the straight-through estimator to allow gradients despite discrete sampling.
The following diagram illustrates this crucial mechanism:
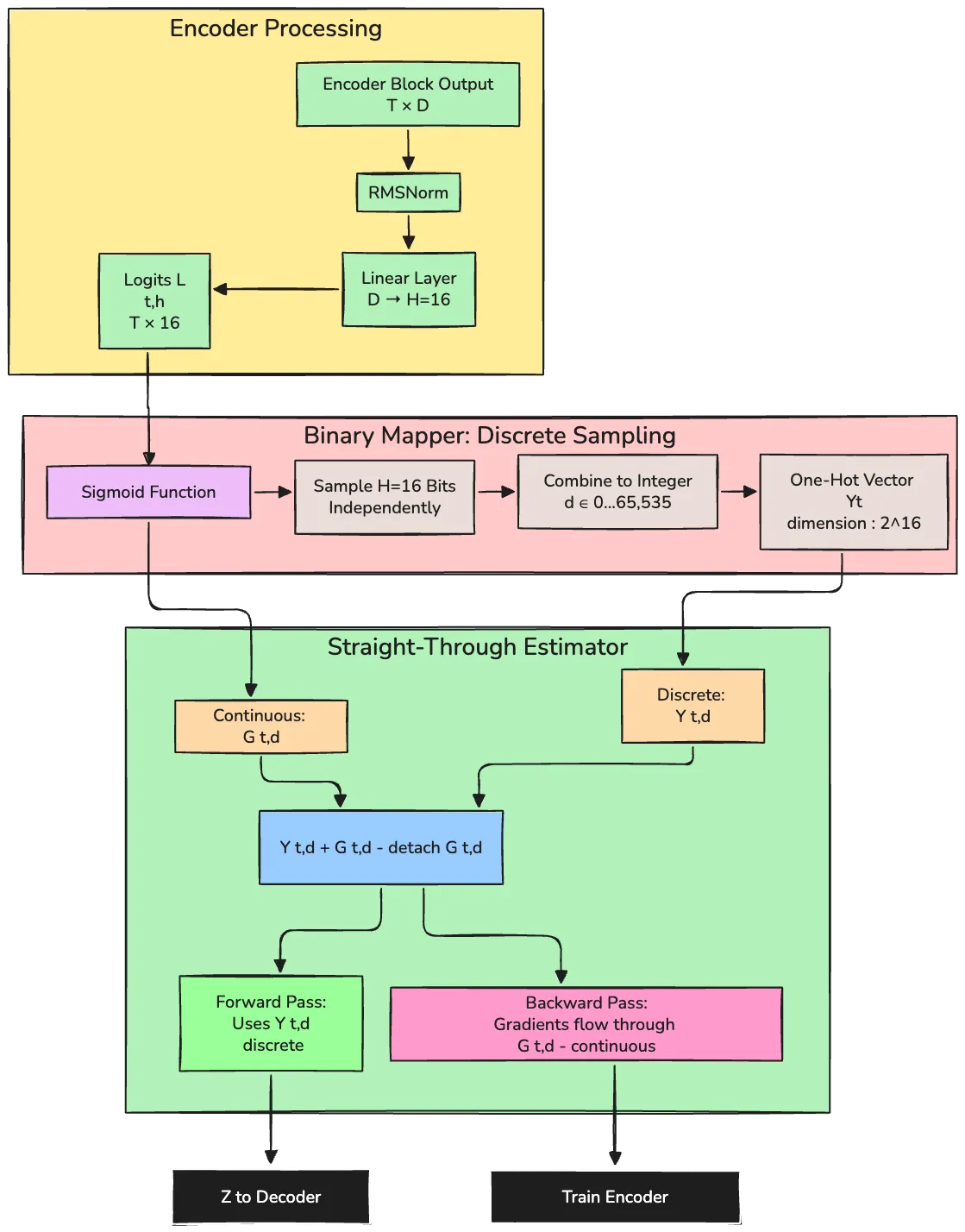 Figure 2: The Binary Mapper converts continuous encoder logits into discrete one-hot vectors representing latent plans. It uses 16 independent binary choices to create 2^16 = 65,536 possible plans per token. The straight-through estimator solves the non-differentiability problem: the forward pass uses discrete samples, while gradients flow through continuous probabilities, enabling end-to-end training.[1]
Figure 2: The Binary Mapper converts continuous encoder logits into discrete one-hot vectors representing latent plans. It uses 16 independent binary choices to create 2^16 = 65,536 possible plans per token. The straight-through estimator solves the non-differentiability problem: the forward pass uses discrete samples, while gradients flow through continuous probabilities, enabling end-to-end training.[1]
The Straight-Through Estimator: This technique enables gradient backpropagation through discrete sampling:
output = Yₜ,ᵈ + Gₜ,ᵈ - detach(Gₜ,ᵈ)
Where:
- Yₜ,ᵈ: The discrete one-hot vector (sampled)
- Gₜ,ᵈ: The continuous probability of sampling that vector
- detach(·): Stops gradient flow
Forward pass: The Gₜ,ᵈ - detach(Gₜ,ᵈ) term evaluates to zero, so output is the discrete Yₜ,ᵈ.
Backward pass: Gradients flow through Gₜ,ᵈ but are blocked by detach, effectively approximating the gradient of the discrete sample with the gradient of its probability. This allows the encoder to learn despite the discrete bottleneck.
Training: The VAE Framework
Training requires balancing two competing objectives: the decoder must learn useful information from Z, but Z must remain simple enough for random sampling at inference.
Conditional Variational Autoencoder (CVAE): A Variational Autoencoder (VAE) is a framework for learning latent variable models. It consists of an encoder that maps data to latent variables Q(Z | S) and a decoder that maps latent variables to data P(S | Z). The VAE is trained to maximize P(S) = ∫ P(S | Z)P(Z) dZ, which is intractable. Instead, it optimizes a lower bound:
log P(S) ≥ 𝔼[log P(S | Z)] - D_KL(Q(Z|S) || P(Z))
The Free Transformer uses a conditional VAE structure where the decoder is the main generative model, and the encoder exists only to provide training signals.
The Two-Part Loss Function
The training objective balances reconstruction quality with information control:
1. Reconstruction Loss
Standard cross-entropy between predicted and actual next tokens:
ℒ_recon = -∑ᵗₜ₌₁ log P(Sₜ | S₍ₜ, Z)
This ensures the decoder learns to generate accurate sequences when following the encoder's plans.
2. KL Divergence Loss (with Free Bits)
The KL divergence regularizes the encoder:
ℒ_KL = (1/T) ∑ᵗₜ₌₁ max(0, D_KL(Q(Zₜ|S) || P(Zₜ)) - κ)
This measures how much the encoder's distribution Q(Z | S) deviates from the uniform prior P(Z). The max(0, · - κ) implements "free bits": only penalize information exceeding the budget κ.
The following diagram visualizes how these components work together in the training framework:
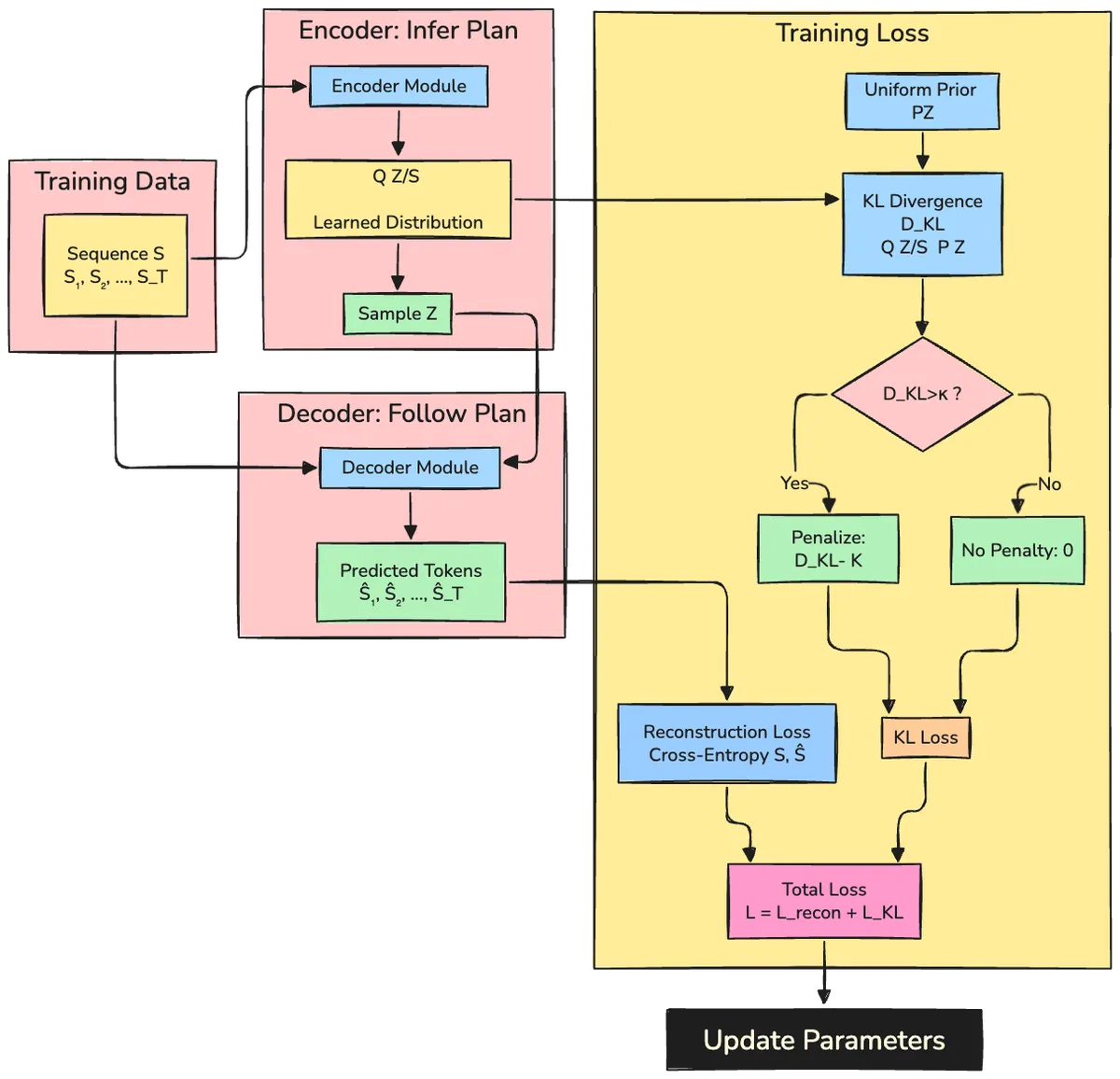
Figure 3: The Free Transformer uses a VAE training objective with two competing goals: the reconstruction loss ensures Z contains useful information for generation, while the KL divergence loss prevents the encoder from transmitting too much information. The "free bits" mechanism (threshold κ) allows the encoder an information budget—only KL divergence exceeding κ is penalized. The optimal value (κ ≈ 0.5 bits per token for 8B models) balances these objectives, enabling Z to capture high-level structure like sentiment and topic without encoding full token details.[1]
Understanding KL Divergence: The KL divergence D_KL(Q || P) measures how much one probability distribution Q differs from another distribution P. In the VAE framework, D_KL(Q(Z|S) || P(Z)) measures the "information cost" of the encoder's distribution compared to the prior. Higher KL means the encoder is packing more information into Z, making it more complex. For the uniform prior P(Zₜ = z) = 1/2¹⁶, the KL divergence simplifies to:
D_KL(Q(Zₜ|S) || P(Zₜ)) = 16 log 2 + ∑_z Q(Z = z | S) log Q(Z = z | S)
Minimizing this encourages the encoder to produce distributions close to uniform, preventing it from encoding too much information.
The Goldilocks Problem
The information budget κ (kappa) must be carefully tuned:
Too small (κ → 0): The encoder can't transmit useful information; Z is ignored, and the model behaves like a standard Transformer with no benefit.
Just right (κ ≈ 0.5 bits): Z captures high-level structure like position, sentiment, and topic, leading to performance gains.
Too large (κ ≥ 4 bits): The encoder "cheats," encoding too much detail. The decoder becomes dependent on training-only information and fails at inference when given random Z.
Free Bits Explained: The "free bits" technique prevents KL divergence collapse—a common VAE failure where the model learns to ignore Z entirely by setting D_KL ≈ 0. Instead of always penalizing KL divergence, free bits allows the encoder an "information budget" κ per token. Only KL divergence exceeding κ is penalized. This ensures Z carries at least κ bits of information. In the paper, the best 8B model used κ = log(2)/2, corresponding to 0.5 bits of information per token.
The paper found κ = log(2)/2 (0.5 bits per token) optimal for 8B models trained on 1T tokens.
Seeing It in Action: The Synthetic Experiment
To verify that Z genuinely captures structure, the paper designed a controlled experiment that beautifully demonstrates the model's learning behavior.
The Letter Placement Task
Each synthetic sequence consists of:
- 64 underscores:
________________________________________________________________ - A random uppercase letter at a random position, repeated 8 times:
JJJJJJJJ - Random exclamation marks as noise (probability 1/16)
- A prompt:
J:indicating the target letter
Example: J: ____________JJJJJJJJ!_______!____!______________________
The task tests whether Z learns to encode the position of the 8-letter block—a clear latent structure.
What Z Learns at Different Information Levels
Training multiple models with different κ values, the paper generated sequences in two ways:
- Different Z per sequence: Each sequence gets independently sampled Z.
- Same Z for all sequences: Multiple sequences share the same Z.
The results reveal exactly what Z encodes:
κ = log(2)/64 (1/64 bit per token): Sequences with the same Z look identical to sequences with different Z—Z carries no information. The model behaves like a standard Transformer.
κ = log(2)/8 (1/8 bit per token): Sequences sharing the same Z place the 8-letter block at the same position, while sequences with different Z vary. Z has learned to encode position.
κ = log(2) (1 bit per token): Z encodes both position and noise patterns. Sequences with shared Z show identical noise patterns across the sequence.
κ = 8 log(2) (8 bits per token): The model generates invalid sequences—no longer blocks of 8 letters. The encoder transmitted too much information during training; the decoder never learned the task properly and fails when given random Z at inference.
This experiment beautifully demonstrates the balance: enough information for Z to be useful, but not so much that the decoder becomes dependent on training-only information.
Implementation
You can easily reproduce the Free Transformer’s synthetic data generation, training, and benchmarking using GitHub implementation. This lets you directly observe how latent planning affects generation and compare results to a baseline Transformer.
Github - Free-transformer : https://github.com/udapy/free-transformer
The Bigger Picture
Chain-of-Thought in Latent Space
The Free Transformer shares conceptual similarities with chain-of-thought reasoning. Both involve intermediate representations that guide final outputs:
| Aspect | Chain-of-Thought | Free Transformer |
|---|---|---|
| Representation | Explicit tokens (visible) | Latent variables (hidden) |
| Training | Reinforcement learning | Variational autoencoder |
| Interpretability | Human-readable steps | Opaque latent codes |
| Efficiency | Adds token overhead | Minimal compute overhead |
The paper suggests these approaches could be combined: explicit reasoning tokens for interpretability, latent variables for implicit structural decisions. This hybrid could capture the best of both worlds.
Future Directions
Promising Avenues:
- Scaling: Performance at larger model sizes (>8B parameters) and training scales (>1T tokens) remains unexplored.
- Hierarchical Latents: Multiple Z variables at different architectural depths, capturing structure at multiple levels.
- Hybrid Reasoning: Combining explicit chain-of-thought tokens with latent planning.
- Adaptive Information Budgets: Learning κ per task or per training stage.
Open Questions:
- Optimization Stability: Training curves show instability. Could separate optimizers for encoder/decoder improve this?
- Latent Structure: What exactly does Z encode in large-scale models? Visualization and interpretability techniques could provide insight.
- Distribution Mismatch: Even with KL regularization, Q(Z | S) during training differs from P(Z) at inference. Can this gap be reduced?
- Task Specificity: Why do reasoning tasks benefit more than knowledge retrieval? Understanding this could guide architecture design.
Limitations
The paper is transparent about constraints:
- Hyperparameter Sensitivity: Performance depends heavily on tuning κ, and optimal values may vary across tasks and scales.
- Training Complexity: The coupled encoder-decoder optimization can be unstable.
- Black Box Latents: Unlike explicit reasoning, Z is not interpretable.
- Mixed Results: Not all benchmark categories show improvements.
Despite these limitations, the Free Transformer represents a conceptual advance—proof that decoder Transformers can learn to leverage latent plans in an unsupervised manner.
Final Thoughts
The Free Transformer challenges a fundamental assumption of modern language models: that autoregressive generation must operate purely at the token level. By introducing learned latent variables that capture high-level plans, it demonstrates that models can separate strategic decisions from tactical execution. The architecture is elegant—a single additional encoder block during training, minimal overhead, and strong gains on reasoning-heavy tasks. The dual-mode design (encoder during training, random sampling during inference) provides a training signal that teaches the decoder to interpret abstract plans without requiring labeled latent variables. The synthetic experiment provides compelling evidence that Z learns meaningful structure: at appropriate information budgets, it captures exactly the kind of high-level decisions (like position and sentiment) that we'd want it to represent. The real-world benchmarks show this translates to practical improvements, particularly on tasks requiring structured reasoning. While questions remain about scaling, stability, and interpretability, the Free Transformer opens a new direction in Transformer research. It shows that the rigid autoregressive paradigm can be relaxed without sacrificing the fundamental strengths of the architecture. As the field continues to push the boundaries of what language models can do, approaches like this—which give models more expressive ways to structure their internal computations—will be essential. The name "Free Transformer" is apt. By giving the model freedom to make latent decisions, we may be freeing it from the constraints of purely sequential thinking.
Github: https://github.com/udapy/free-transformer
References:
[1] Fleuret, F. (2025). The Free Transformer. arXiv:2510.17558. Retrieved from https://arxiv.org/abs/2510.17558
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. https://arxiv.org/abs/1706.03762
[3] Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114. https://arxiv.org/abs/1312.6114
[4] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288. https://arxiv.org/abs/2307.09288