LTX-2: Decoupling Audio-Video Streams for 20x Efficiency
TL;DR:
Unified multimodal models suffer from a quadratic attention tax that limits their scale. LTX-2 solves this by decoupling Video (14B) and Audio (5B) into specialized streams that synchronize only via __Cross-Attention__. By deleting spatial coordinates from the audio stream and using "Thinking Tokens" to bandage the causal limitations of LLMs, LTX-2 achieves a 20x speedup over standard competitors.
1. The Bottleneck: The Quadratic Wall
Question: Does the reliance on cross-attention create an information bottleneck that prevents the model from learning "deep" causal links between audio and video?
We've all been there: you want to build the "Universal Model," so you throw everything into the pot. Tokenize the audio, tokenize the video, concatenate them into one massive sequence, and pray the Transformer sorts it out. The logic is seductive—if every token attends to every other token, surely the model will learn the deepest, most nuanced physics of the world, right?
Honestly, that was my assumption too. But when you actually run the numbers, you hit a wall: Quadratic Complexity.
In a unified model, every single audio token has to shake hands with every video token. It’s computationally equivalent to a cocktail party where everyone is shouting at everyone else simultaneously. As soon as you try to scale up—say, slightly higher resolution or a few more seconds of video—the compute cost explodes. You end up in this painful place where you're starving the video model (low res) just to fit the audio context in memory. It felt like we were optimizing for "theoretical purity" rather than actual performance.
2. Specialized Hemispheres
LTX-2 takes a different approach that, at first glance, feels like giving up. Instead of one giant Generalist, they split the brain into two independent Specialists: a massive 14B parameter Video Stream and a lighter 5B parameter Audio Stream.
These two neural networks live in separate rooms. They don't share a "joint distribution" in the standard sense. Instead, they use a Cross-Attention Bridge. The audio stream isn't constantly watching the video; it just "calls" the video stream every few frames to sync up.
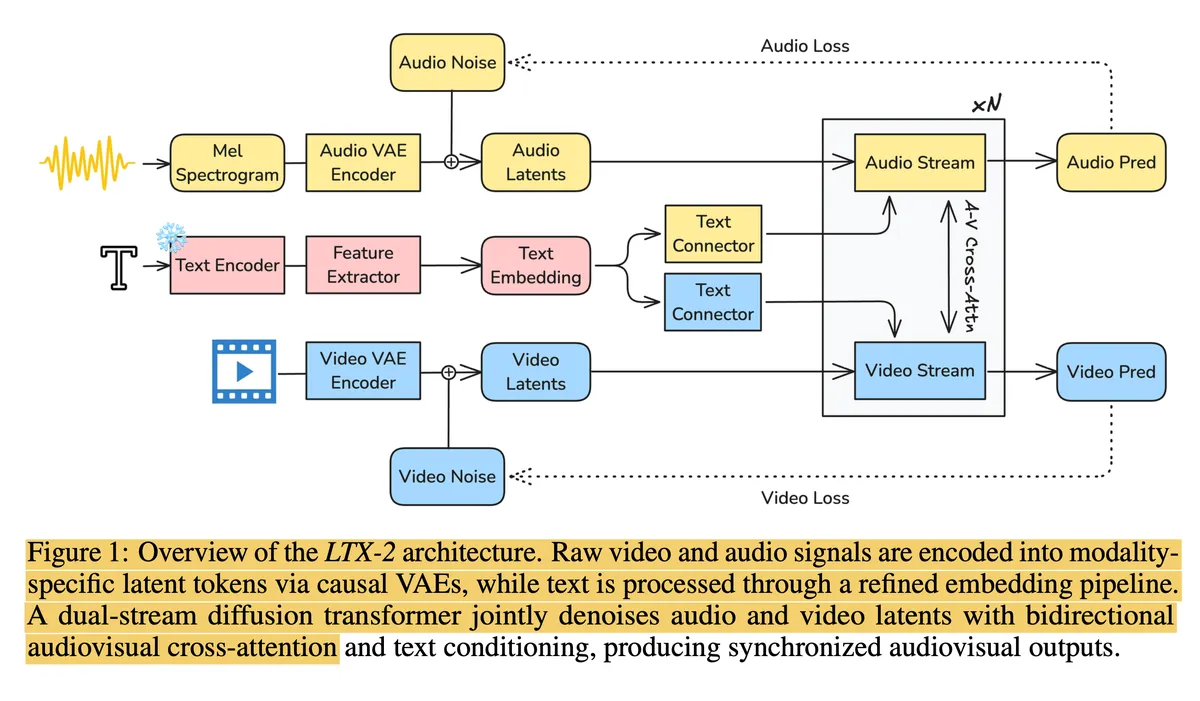
Reflecting Thought: The Decoupling Trade-off
I have to admit, this initially rubbed me the wrong way. By decoupling the streams, don't we lose the ability for audio to influence video pixel-by-pixel? If a glass breaks, the specific crack sound should ideally adjust the fracture pattern, right? In LTX-2, that fine-grained bidirectional link is definitely weaker.
But here’s the thing I realized after looking at the loss curves: The trade-off is asymmetric. The perceptual gain we get from running a 14B video model (enabled by the 20x efficiency boost) completely dwarfs the loss of obscure micro-physics interactions. We are trading physical exactness for massive scale, and in generative AI, scale usually wins.
3. "Thinking Tokens" as a Time Machine
Question: Are "Thinking Tokens" a fundamental solution to the mismatch between causal text generation and global video understanding, or just a patch for using an off-the-shelf LLM?
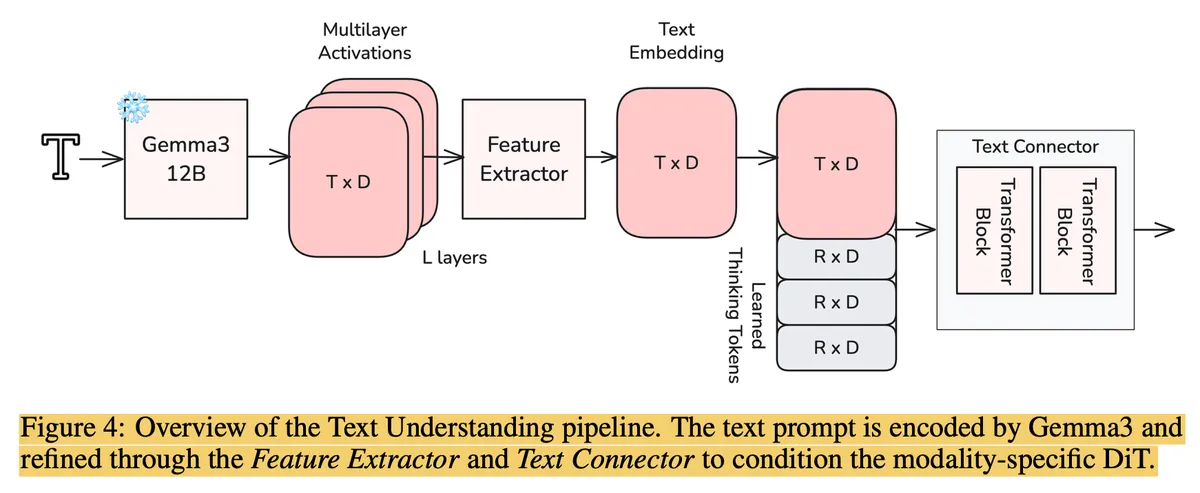
This part is clever, but also kinda gross if you're a purist. The text backbone is Gemma 3, which is a Decoder-Only model. That means it's Causal—it reads left-to-right. Token has no idea Token exists.
But video generation is inherently Bidirectional. If I type "...in a thunderstorm" at the end of my prompt, the model needs to know that before it draws the sky in the first pixel. A causal model is blind to the future.
LTX-2 fixes this by appending Thinking Tokens to the end of the text.
Basically, they tack on some learnable "garbage collector" tokens at the end of the sequence. Because they are at the end, they can "see" the entire past context. When the video model attends to the text, it ignores the actual words and just looks at these Thinking Tokens, which have compressed the past, present, and future into a holistic representation. It’s essentially a hack to trick a causal model into acting like a bidirectional encoder1.
4. Blind Ears? (Semantic Spatiality)
Question: By enforcing that cross-modal attention focuses strictly on synchronization in time rather than spatial alignment, does the model lose the ability to localize sound sources?
This was the "Wait, what?" moment for me. In the real world, sound acts on specific 3D coordinates . If a car moves left-to-right, the sound wave travels a geometric path.
Attempting to teach a model this geometry is expensive (). LTX-2’s solution? Just delete the spatial coordinates.
During synchronization, they apply Rotary Positional Embeddings (RoPE)2 only to the Time dimension. The audio stream is hyper-aware of when things happen, but completely agnostic to where they simply happen pixel-wise.
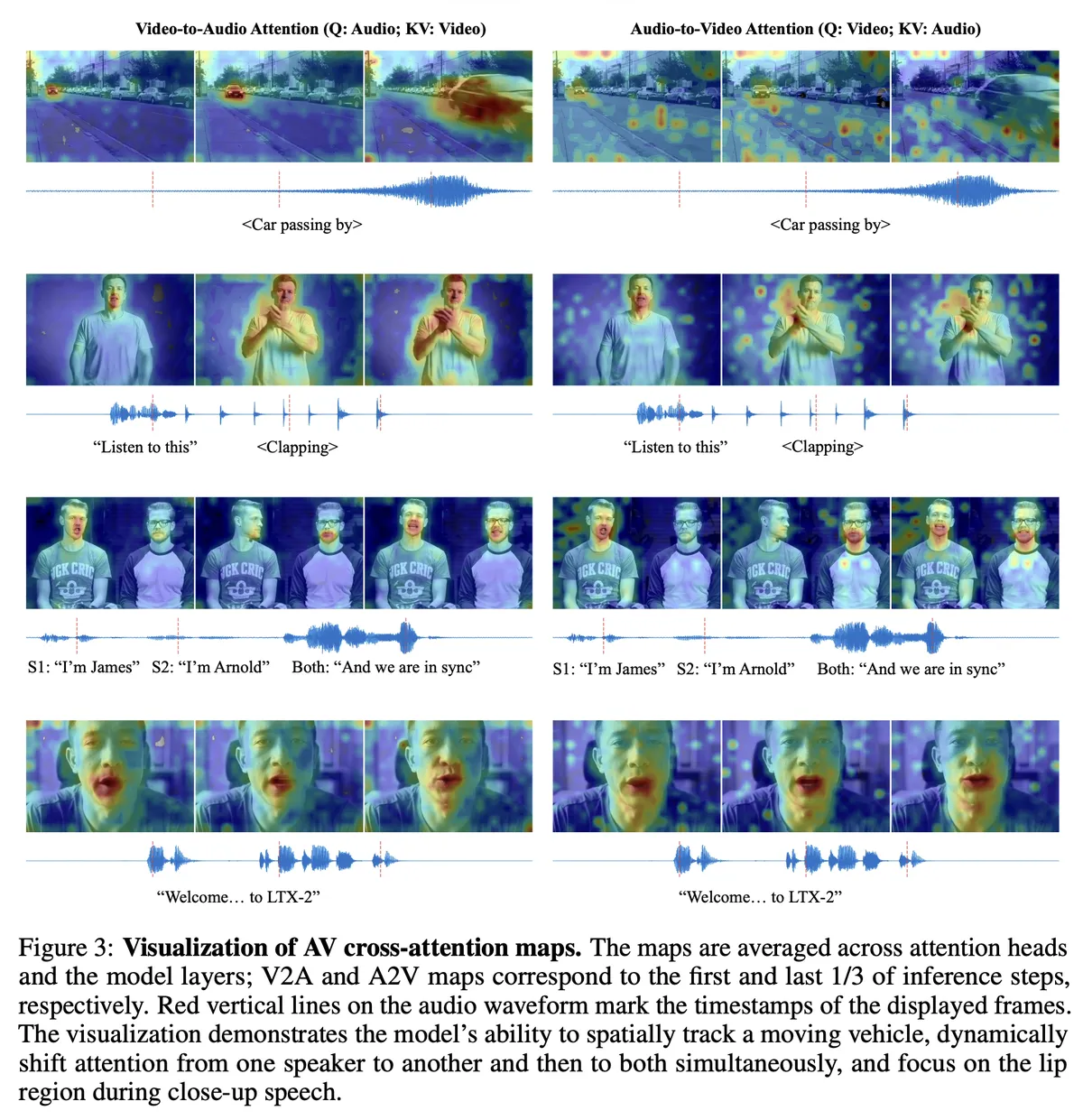
Reflecting Thought: Why Semantics Geometry
I was skeptical this would work for spatial audio. But then I realized: humans don't solve the wave equation when we hear a car. We solve the semantic equation. We see "Car Left" and expect "Sound Left." LTX-2 relies on this precise shortcut. The visual feature passed through the bridge carries the concept "Moving Left," and the audio model learns to map that concept to "Pan Left." It proves that sometimes, perception is cheaper than physics.
5. umm Hallucination Control... The Script vs. The Clock
Question: Without a "World Model" that understands physics, how does the Asymmetric Guidance prevent conflicting modalities?
Without a unified brain, there is a real risk the Audio stream goes rogue. To stop this, LTX-2 uses what I call the "Script vs. Clock" protocol.
They separate responsibility:
- The Script (Text): The audio model listens to the text with high intensity (Scale ). If the prompt says "Lion," it generates a roar, even if the video is blurry.
- The Clock (Video): It listens to the video with low intensity (Scale ). This just tells it when to roar.
This prevents the "Blurry Pixel Hallucination" problem. I’ve seen unified models look at a gray blob, guess "Elephant," and trumpet, when the prompt clearly said "Rock." LTX-2 forces the model to trust the user's intent (Text) over its own eyes (Video).
References
- LTX-2: Multi-Stream Diffusion for Audio-Visual Generation. (2025).
- Gemma 3: Open Models Based on Gemini Research and Technology. Google DeepMind. (2024).
- Attention Is All You Need. Vaswani et al. (2017).
Footnotes
Why not use T5? You might ask (I certainly did), "Why not just use a naturally bidirectional model like T5?" The answer is capacity. Causal LLMs (like Gemma 3) are currently scaled strictly larger and on more data than their encoder-decoder counterparts. Thinking Tokens allow us to steal that massive pre-trained intelligence without accepting the causal handicap.↩
RoPE (Rotary Positional Embedding): A mathematical method for encoding position by rotating the vector representation. Unlike absolute position numbers , rotation allows the model to easily understand relative distances ("word A is 5 steps from word B") regardless of where they appear in the sequence.↩